
The best way to get discovered in Google is to be found by crawlers as a link from other pages
Web Dev Myths in Crawling
There are some serious myths about crawling and indexing files – especially within Web Dev circles that I’m trying hard to challenge and change
- You can optimize crawling
- More crawling = better indexing/indexing
- Less crawling of thin content = more crawling of important files
- Google must read your XML Sitemap Regularly
- Crawling is expensive or Google “needs to save” money
These are all intertwined and all wrong
How does Google schedule global crawling
Crawling is based on Authority (Matt Cutts) – pure and simple. That’s how Google “triages” the web. It also has a number of specialist crawling services – like Caffeine and others that refresh News and Discover content or “QDF” content. Very high authority sites like CNN literally have crawlers that refresh their XML sitemaps.
Difference between Crawling and Indexing in GSC
Crawling Overview
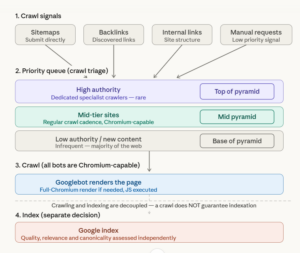
Crawling and Indexing are separated. This means even if you can create lots of links or manual or automated crawl requests, it doesnt result on indexation
Crawling incurs a crawl request – via a priority q. Priority Queues are crawl lists that have specialist crawlers assigned. You need a lot of authority to do this
While almost all Google crawlbots are the same (and fully Chromium, if needed) – they are arranged in different groups. This is how Google triages between the most important sites and looking for new content or posts vs the large base of the pyramid that doesn’t rank or get clicks
Crawling in Google GSC
Most sites do not get regular sitemap refreshes
Crawled not indexed is a common error especially for new and small sites.


